Composed Image Retrieval on Real-life Images
Composed Image Retrieval (or, Image Retreival conditioned on Language Feedback) is a relatively new retrieval task, where an input query consists of an image and short textual description of how to modify the image.
For humans the advantage of a bi-modal query is clear: some concepts and attributes are more succinctly described visually, others through language. By cross-referencing the two modalities, a reference image can capture the general gist of a scene, while the text can specify finer details.
We identify a major challenge of this task as the inherent ambiguity in knowing what information is important (typically one object of interest in the scene) and what can be ignored (e.g., the background and other irrelevant objects).
Here, we extend the task of composed image retrieval by introducing the Composed Image Retrieval on Real-life images (CIRR) dataset - the first dataset of open-domain, real-life images with human-generated modification sentences.
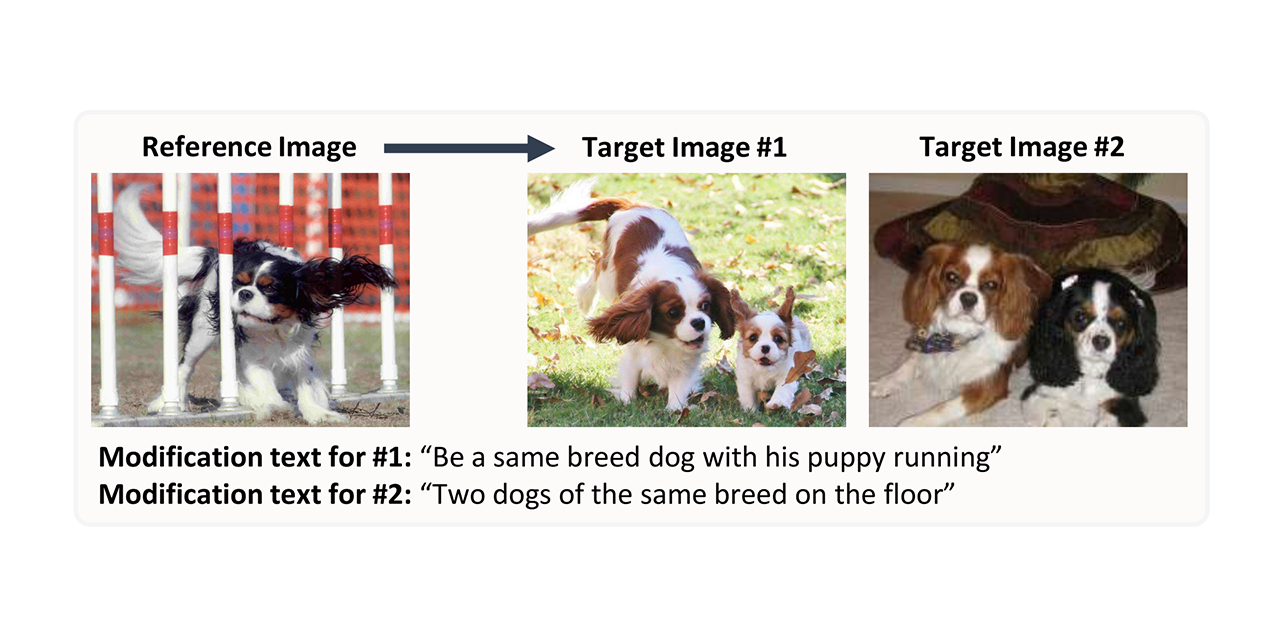
Concurrently, we release the code and pre-trained models for our method Composed Image Retrieval using Pretrained LANguage Transformers (CIRPLANT). Together with the dataset, we believe this work will inspire further research on this task on a finer-grain level.
Read more in our published paper.
View our 5-minute video.
You are currently viewing the Project homepage. Dataset and code repositories are listed below.
CIRR Dataset
We do not publish the ground truth for the test split of CIRR. Instead, we host an evaluation server, should you prefer to publish results on the test-split.
Note, the ground truth for the validation split is available as usual and can be used for development.
CIRPLANT Model
Our code is in PyTorch, and is based on PyTorch Lightning.
News
- Aug. 2021: We have opened our test-split evaluation server.
- Aug. 2021: We are releasing our dataset and code for the project.
Licensing
-
We have licensed the code and annotations of CIRR under the MIT License. Please refer to the LICENSE file for details.
-
Following NLVR2 Licensing, we do not license the images used in CIRR, as we do not hold the copyright to them.
-
The images used in CIRR are sourced from the NLVR2 dataset. Users shall be bounded by its Terms of Service.
Citation
Please cite our paper if it helps your research:
@InProceedings{Liu_2021_ICCV,
author = {Liu, Zheyuan and Rodriguez-Opazo, Cristian and Teney, Damien and Gould, Stephen},
title = {Image Retrieval on Real-Life Images With Pre-Trained Vision-and-Language Models},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {2125-2134}
}
Contact
If you have any questions regarding our dataset, model, or publication, please create an issue in the project repository, or email us.